Publications
* indicates equal contribution.
2026
-
 Information Asymmetry Across Language Varieties: A Case Study on Cantonese-Mandarin and Bavarian-German QARenhao Pei*, Siyao Peng*, Verena Blaschke, and 2 more authorsarXiv preprint arXiv:2603.14782, 2026
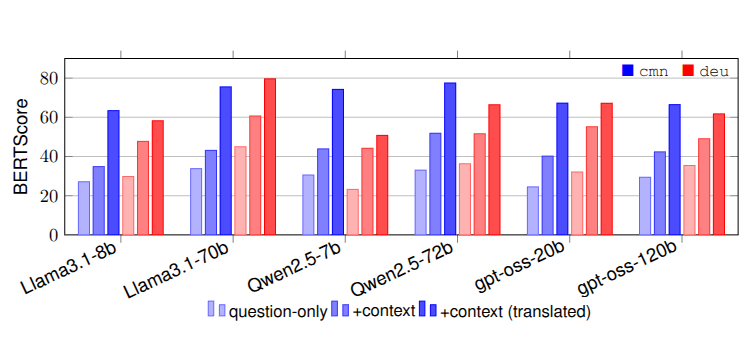
Information Asymmetry Across Language Varieties: A Case Study on Cantonese-Mandarin and Bavarian-German QARenhao Pei*, Siyao Peng*, Verena Blaschke, and 2 more authorsarXiv preprint arXiv:2603.14782, 2026Large Language Models (LLMs) are becoming a common way for humans to seek knowledge, yet their coverage and reliability vary widely. Especially for local language varieties, there are large asymmetries, e.g., information in local Wikipedia that is absent from the standard variant. However, little is known about how well LLMs perform under such information asymmetry, especially on closely related languages. We manually construct a novel challenge question-answering (QA) dataset that captures knowledge conveyed on a local Wikipedia page, which is absent from their higher-resource counterparts—covering Mandarin Chinese vs. Cantonese and German vs. Bavarian. Our experiments show that LLMs fail to answer questions about information only in local editions of Wikipedia. Providing context from lead sections substantially improves performance, with further gains possible via translation. Our topical, geographic annotations, and stratified evaluations reveal the usefulness of local Wikipedia editions as sources of both regional and global information. These findings raise critical questions about inclusivity and cultural coverage of LLMs.
-
 Decoupling the Effect of Chain-of-Thought Reasoning: A Human Label Variation PerspectiveBeiduo Chen, Tiancheng Hu, Caiqi Zhang, and 3 more authorsarXiv preprint arXiv:2601.03154, 2026
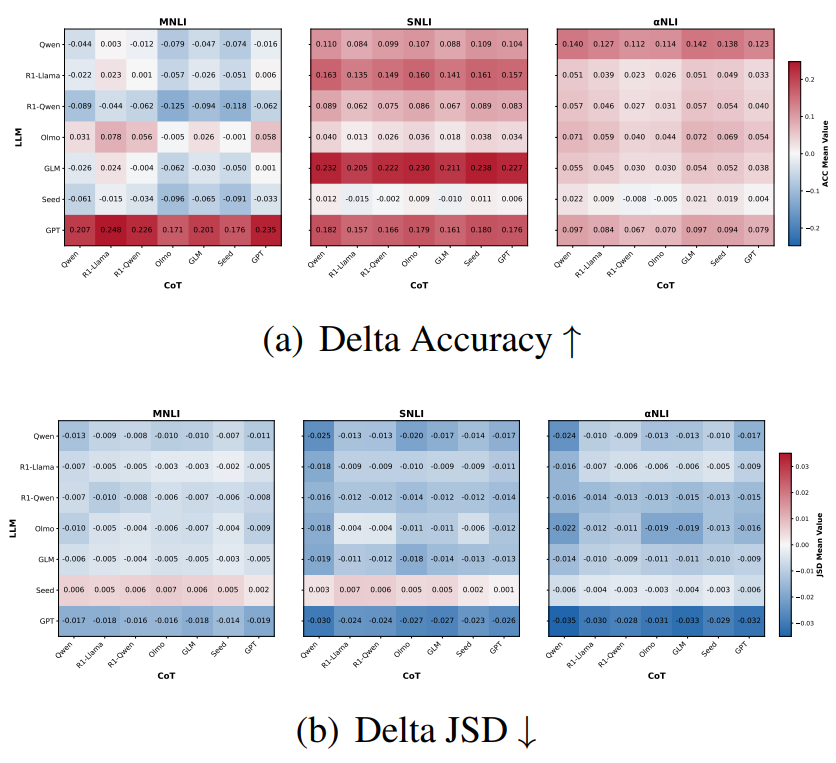
Decoupling the Effect of Chain-of-Thought Reasoning: A Human Label Variation PerspectiveBeiduo Chen, Tiancheng Hu, Caiqi Zhang, and 3 more authorsarXiv preprint arXiv:2601.03154, 2026Reasoning-tuned LLMs utilizing long Chain-of-Thought (CoT) excel at single-answer tasks, yet their ability to model Human Label Variation—which requires capturing probabilistic ambiguity rather than resolving it—remains underexplored. We investigate this through systematic disentanglement experiments on distribution-based tasks, employing Cross-CoT experiments to isolate the effect of reasoning text from intrinsic model priors. We observe a distinct "decoupled mechanism": while CoT improves distributional alignment, final accuracy is dictated by CoT content (99% variance contribution), whereas distributional ranking is governed by model priors (over 80%). Step-wise analysis further shows that while CoT’s influence on accuracy grows monotonically during the reasoning process, distributional structure is largely determined by LLM’s intrinsic priors. These findings suggest that long CoT serves as a decisive LLM decision-maker for the top option but fails to function as a granular distribution calibrator for ambiguous tasks.


2025
-
 Relevant for the Right Reasons? Investigating Lexical Biases in Zero-Shot and Instruction-Tuned RerankersYuchen Mao, Barbara Plank, and Robert LitschkoIn Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), co-located with EMNLP, Nov 2025
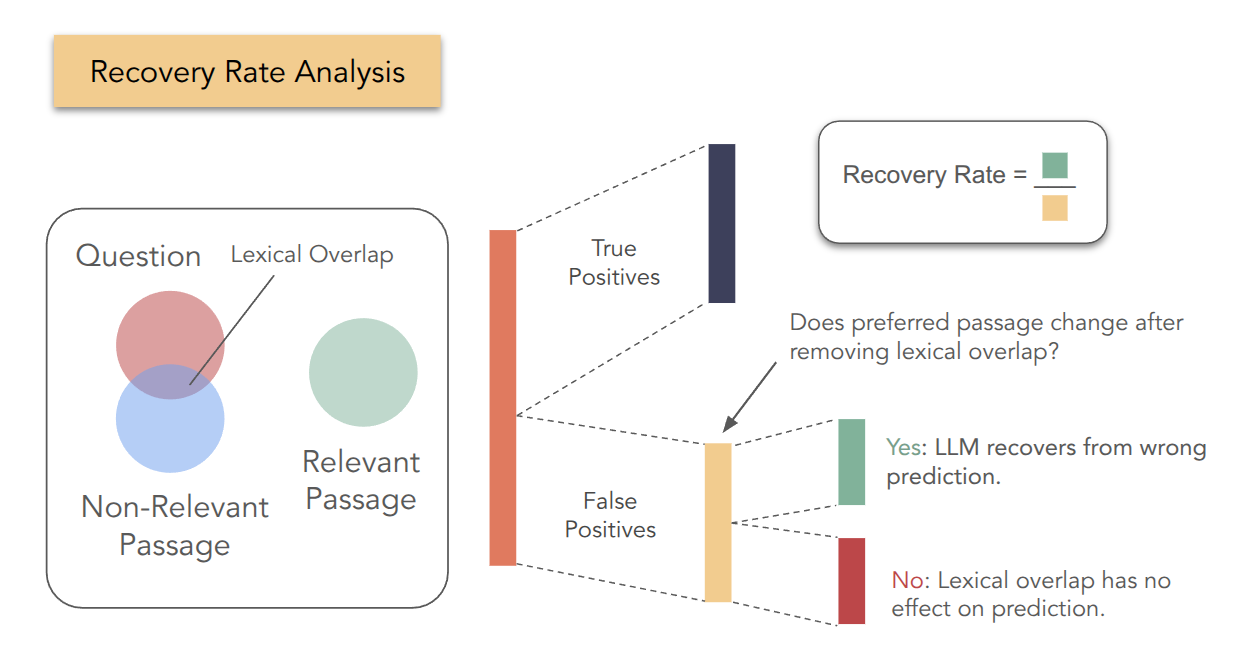
Relevant for the Right Reasons? Investigating Lexical Biases in Zero-Shot and Instruction-Tuned RerankersYuchen Mao, Barbara Plank, and Robert LitschkoIn Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), co-located with EMNLP, Nov 2025Large Language Models (LLMs) show strong potential for reranking documents in information retrieval (IR), but training with monolingual data often leads to monolingual overfitting and lexical bias, limiting generalization in cross-lingual IR (CLIR). To overcome these issues, we investigate instruction-tuning LLaMA-3.1-8B-Instruct on English and multilingual code-switched data, and evaluate on mMARCO and XQuAD-R. Results show that instruction-tuning on code-switched data substantially improves CLIR performance, while monolingual tuning remains more effective for monolingual reranking. We introduce a novel measure to analyze the relationship between lexical overlap and reranking performance, showing that the two factors are correlated. We finally conduct a causal analysis using counterfactual examples, where we evaluate whether rewriting passages that share overlapping keywords with the query causes models to change their relevance predictions. Overall, we find that code-switching serves as an effective and lightweight strategy to improve cross-lingual generalization in LLM-based re-ranking, while our analyses show that lexical overlap remains a major factor that can mislead reranking models.
-
 Make Every Letter Count: Building Dialect Variation Dictionaries from Monolingual CorporaRobert Litschko, Verena Blaschke, Diana Burkhardt, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025
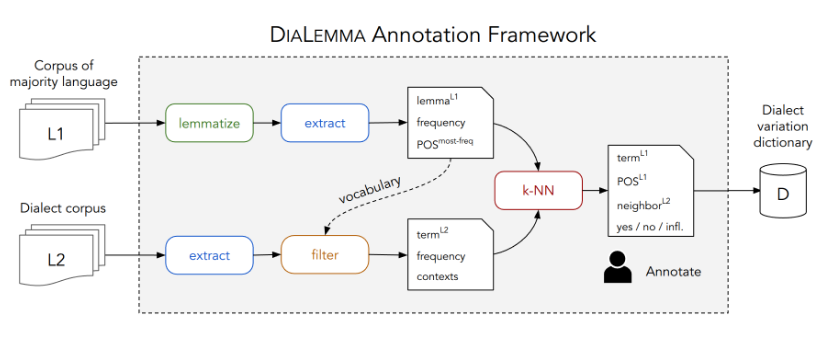
Make Every Letter Count: Building Dialect Variation Dictionaries from Monolingual CorporaRobert Litschko, Verena Blaschke, Diana Burkhardt, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025Dialects exhibit a substantial degree of variation due to the lack of a standard orthography. At the same time, the ability of Large Language Models (LLMs) to process dialects remains largely understudied. To address this gap, we use Bavarian as a case study and investigate the lexical dialect understanding capability of LLMs by examining how well they recognize and translate dialectal terms across different parts-of-speech. To this end, we introduce DiaLemma, a novel annotation framework for creating dialect variation dictionaries from monolingual data only, and use it to compile a ground truth dataset consisting of 100K human-annotated German-Bavarian word pairs. We evaluate how well nine state-of-the-art LLMs can judge Bavarian terms as dialect translations, inflected variants, or unrelated forms of a given German lemma. Our results show that LLMs perform best on nouns and lexically similar word pairs, and struggle most in distinguishing between direct translations and inflected variants. Interestingly, providing additional context in the form of example usages improves the translation performance, but reduces their ability to recognize dialect variants. This study highlights the limitations of LLMs in dealing with orthographic dialect variation and emphasizes the need for future work on adapting LLMs to dialects.
-
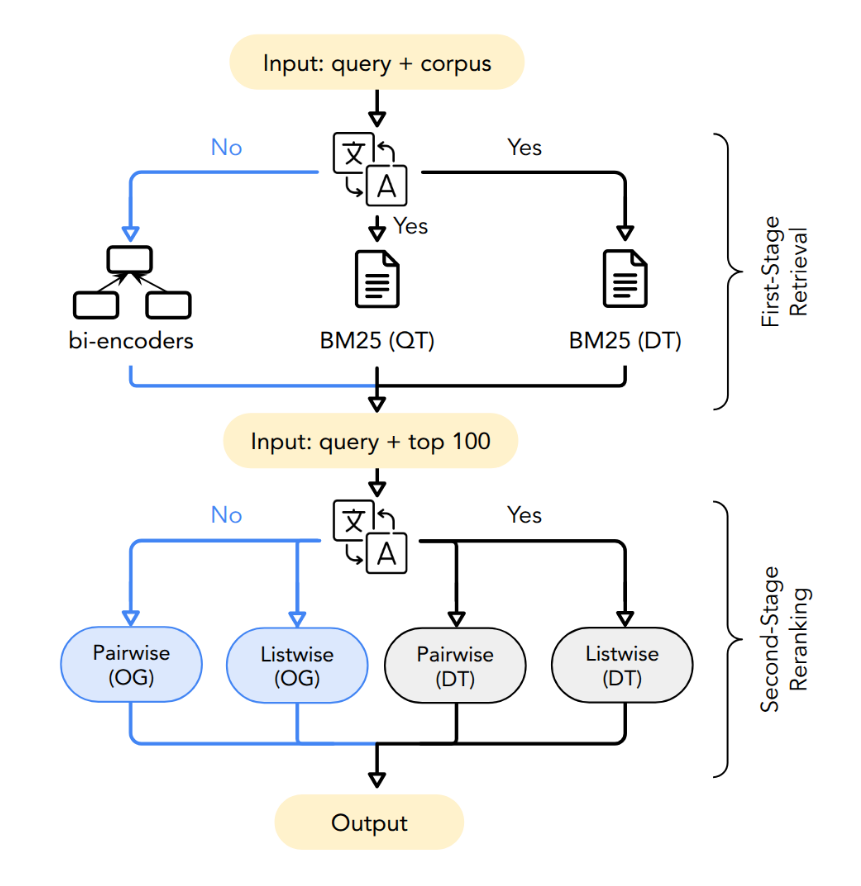 Evaluating Large Language Models for Cross-Lingual RetrievalLongfei Zuo*, Pingjun Hong*, Oliver Kraus, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025
Evaluating Large Language Models for Cross-Lingual RetrievalLongfei Zuo*, Pingjun Hong*, Oliver Kraus, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025Multi-stage information retrieval (IR) has become a widely-adopted paradigm in search. While Large Language Models (LLMs) have been extensively evaluated as second-stage reranking models for monolingual IR, a systematic large-scale comparison is still lacking for cross-lingual IR (CLIR). Moreover, while prior work shows that LLM-based rerankers improve CLIR performance, their evaluation setup relies on lexical retrieval with machine translation (MT) for the first stage. This is not only prohibitively expensive but also prone to error propagation across stages. Our evaluation on passage-level and document-level CLIR reveals that further gains can be achieved with multilingual bi-encoders as first-stage retrievers and that the benefits of translation diminishes with stronger reranking models. We further show that pairwise rerankers based on instruction-tuned LLMs perform competitively with listwise rerankers. To the best of our knowledge, we are the first to study the interaction between retrievers and rerankers in two-stage CLIR with LLMs. Our findings reveal that, without MT, current state-of-the-art rerankers fall severely short when directly applied in CLIR.
-
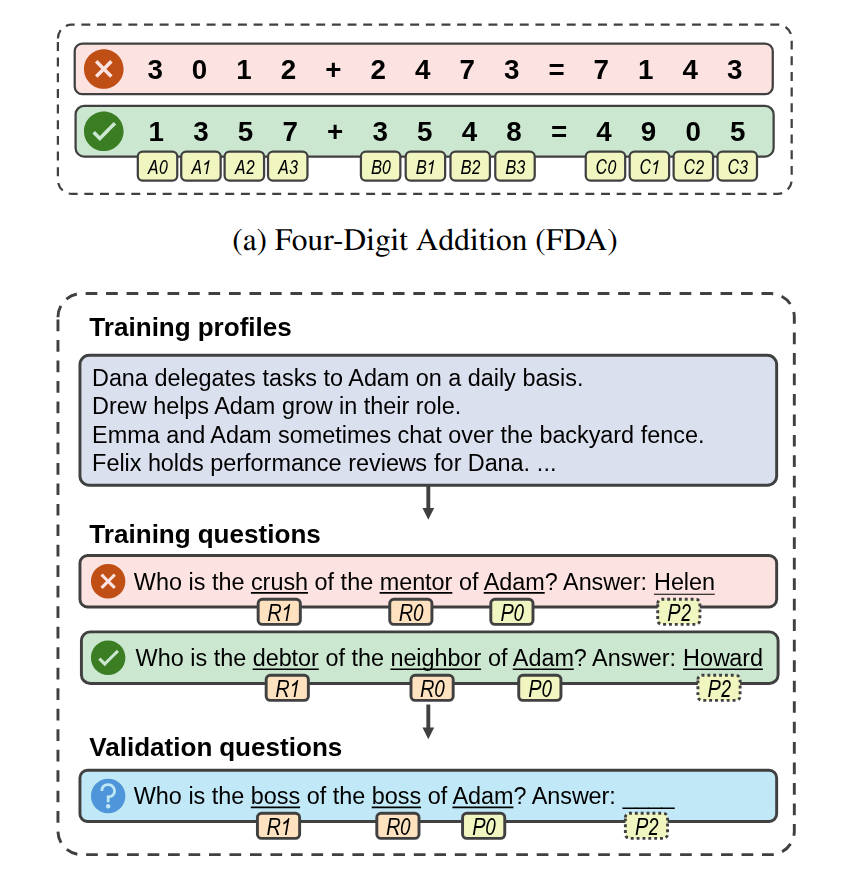 Reason to Rote: Rethinking Memorization in ReasoningYupei Du, Philipp Mondorf, Silvia Casola, and 3 more authorsIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), Nov 2025
Reason to Rote: Rethinking Memorization in ReasoningYupei Du, Philipp Mondorf, Silvia Casola, and 3 more authorsIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), Nov 2025Large language models readily memorize arbitrary training instances, such as label noise, yet they perform strikingly well on reasoning tasks. In this work, we investigate how language models memorize label noise, and why such memorization in many cases does not heavily affect generalizable reasoning capabilities. Using two controllable synthetic reasoning datasets with noisy labels, four-digit addition (FDA) and two-hop relational reasoning (THR), we discover a reliance of memorization on generalizable reasoning mechanisms: models continue to compute intermediate reasoning outputs even when retrieving memorized noisy labels, and intervening reasoning adversely affects memorization. We further show that memorization operates through distributed encoding, i.e., aggregating various inputs and intermediate results, rather than building a look-up mechanism from inputs to noisy labels. Moreover, our FDA case study reveals memorization occurs via outlier heuristics, where existing neuron activation patterns are slightly shifted to fit noisy labels. Together, our findings suggest that memorization of label noise in language models builds on, rather than overrides, the underlying reasoning mechanisms, shedding lights on the intriguing phenomenon of benign memorization.
-
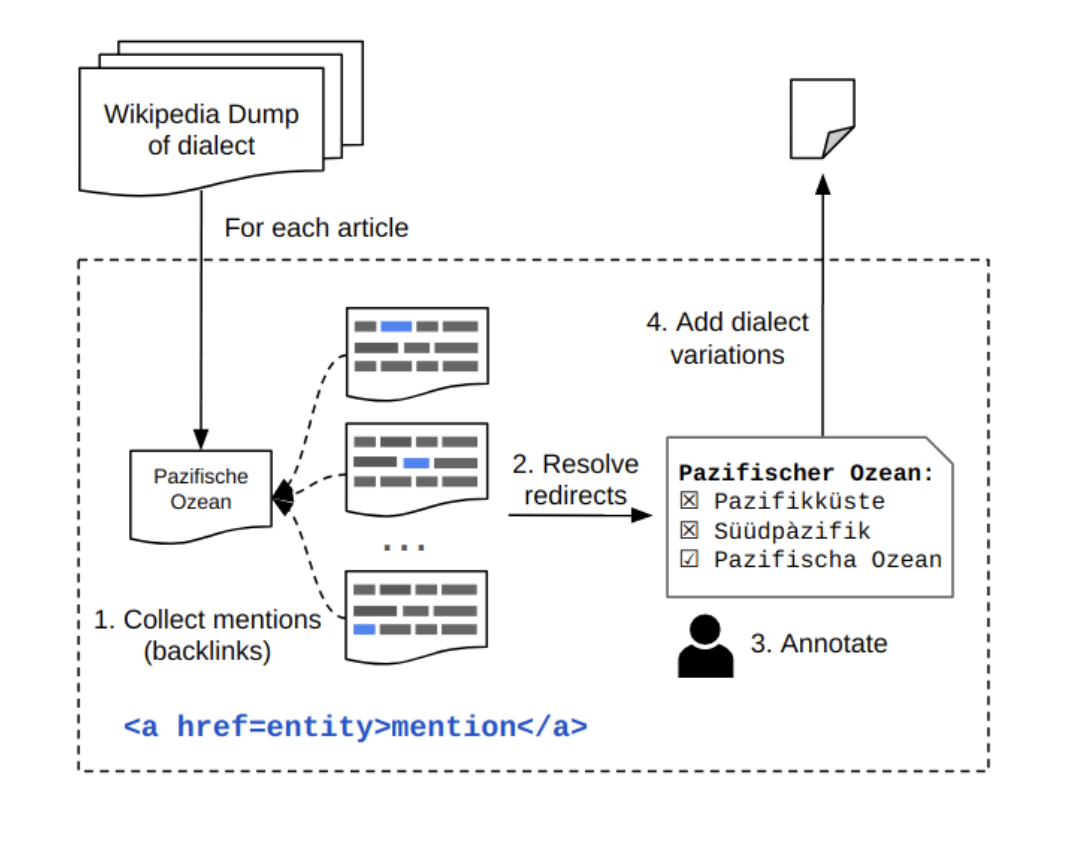 Cross-Dialect Information Retrieval: Information Access in Low-Resource and High-Variance LanguagesRobert Litschko, Oliver Kraus, Verena Blaschke, and 1 more authorIn Proceedings of the 31st International Conference on Computational Linguistics (COLING), Jan 2025
Cross-Dialect Information Retrieval: Information Access in Low-Resource and High-Variance LanguagesRobert Litschko, Oliver Kraus, Verena Blaschke, and 1 more authorIn Proceedings of the 31st International Conference on Computational Linguistics (COLING), Jan 2025A large amount of local and culture-specific knowledge (e.g., people, traditions, food) can only be found in documents written in dialects. While there has been extensive research conducted on cross-lingual information retrieval (CLIR), the field of cross-dialect retrieval (CDIR) has received limited attention. Dialect retrieval poses unique challenges due to the limited availability of resources to train retrieval models and the high variability in non-standardized languages. We study these challenges on the example of German dialects and introduce the first German dialect retrieval dataset, dubbed WikiDIR, which consists of seven German dialects extracted from Wikipedia. Using WikiDIR, we demonstrate the weakness of lexical methods in dealing with high lexical variation in dialects. We further show that commonly used zero-shot cross-lingual transfer approach with multilingual encoders do not transfer well to extremely low-resource setups, motivating the need for resource-lean and dialect-specific retrieval models. We finally demonstrate that (document) translation is an effective way to reduce the dialect gap in CDIR.





2024
-
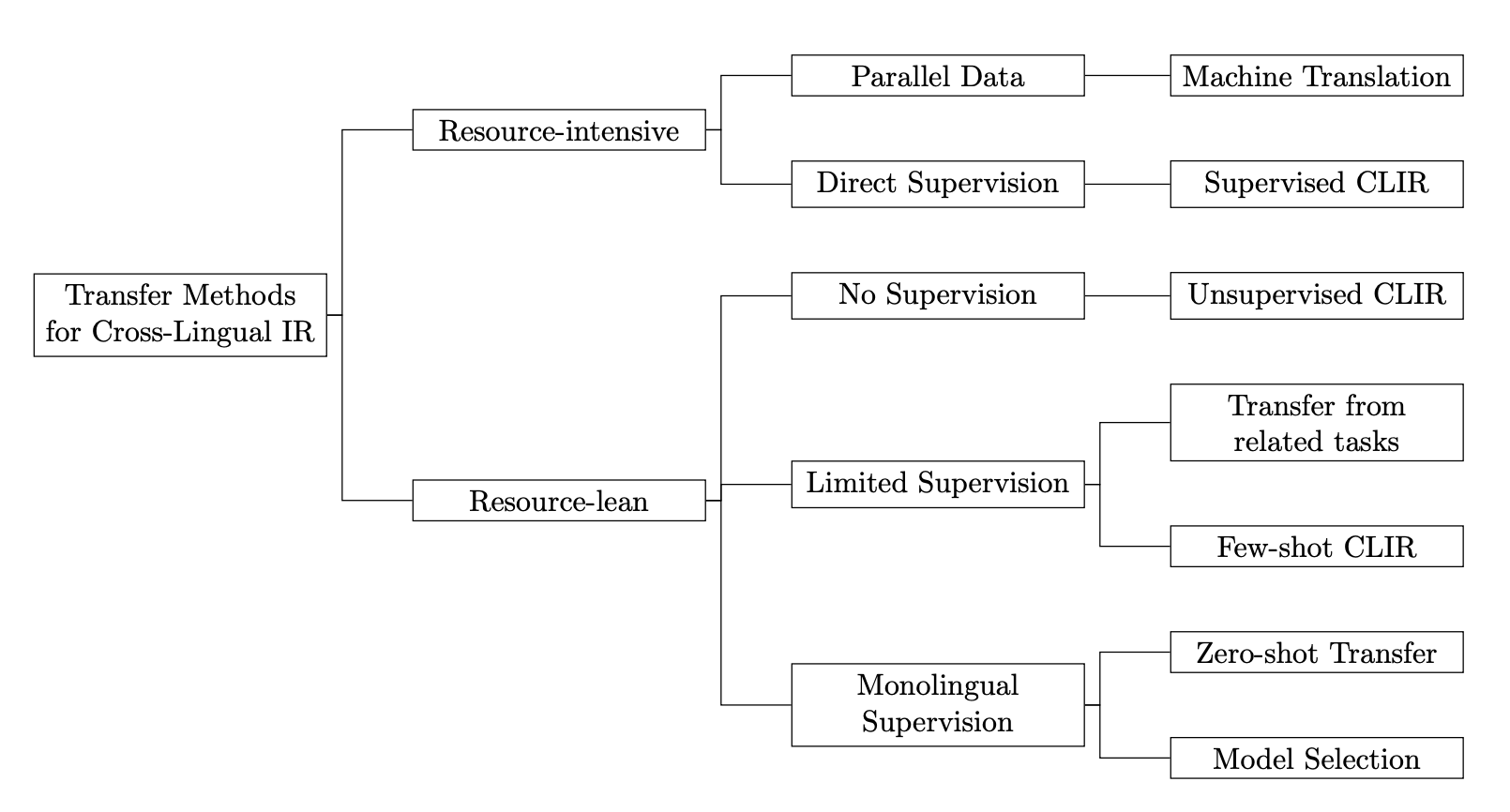 Resource-lean transfer methods for cross-lingual information retrievalRobert LitschkoDissertation, Dec 2024
Resource-lean transfer methods for cross-lingual information retrievalRobert LitschkoDissertation, Dec 2024Cross-Lingual Information Retrieval (CLIR) is the task of finding relevant documents written in a language different from the query language. Neural machine translation systems and CLIR models based on supervised machine learning (deep learning) are resource-hungry approaches requiring large amounts of training data, which is expensive to obtain and therefore does not scale well to a large number of languages. In this thesis, we study methods for transferring retrieval models across languages in a resource-lean way. The overarching goal is to build effective CLIR systems for languages for which we do not have access to large-scale training data. On a high level, our contributions fall into three areas. Unsupervised learning of CLIR models. In the first part, we propose two fully unsupervised neural CLIR approaches for which no relevance annotations are required. In the representation-based approach, we encode queries and documents into independent semantic vector representations and use vector space similarity measures to calculate document relevance scores. Here, we obtain aligned query and document representations from static cross-lingual word embeddings (CLWEs) and contextual representations produced by multilingual text encoders. In the term-by-term query translation approach, we translate query terms by replacing their occurrences with their cross-lingual nearest neighbors found in CLWE spaces, effectively casting CLIR into a noisy variant of monolingual IR (MoIR). We conduct a large-scale evaluation and, surprisingly, find that off-the-shelf multilingual text encoders fall behind CLWE-based methods in a direct comparison, whereas further specialization for sentence-level semantics yields the best results. Resource-lean transfer of CLIR models. In the second part, we focus on the standard zero-shot cross-lingual transfer (ZS-XLT) setup and use English training data to transfer cross-encoder (CE) reranking models to other languages. We first show that this approach suffers from “monolingual overfitting” where models are biased towards lexical matches between query and document tokens. To regularize this bias, we propose to train CEs on code-switched data instead. Our results show that this consistently improves the ZS-XLT performance for CLIR and maintains stable performance in MoIR. Next, we rely on parameter-efficient transfer methods to disentangle the task of learning-to-rank from learning target language semantics. We show that this modular approach improves upon the standard ZS-XLT approach in a scenario where the training and test data are in different domains. In the third part, we present on the example task of multilingual dependency parsing a proof of concept for instance-level model selection. Here, we propose cross-lingual transfer with multiple monolingual expert models by using a routing model. Moving away from a single multilingual model bypasses any capacity limits in terms of number of languages (“curse of multilinguality”). Our results pave the way for future work on CLIR involving multiple encoders (e.g. language-family specific encoders).
-
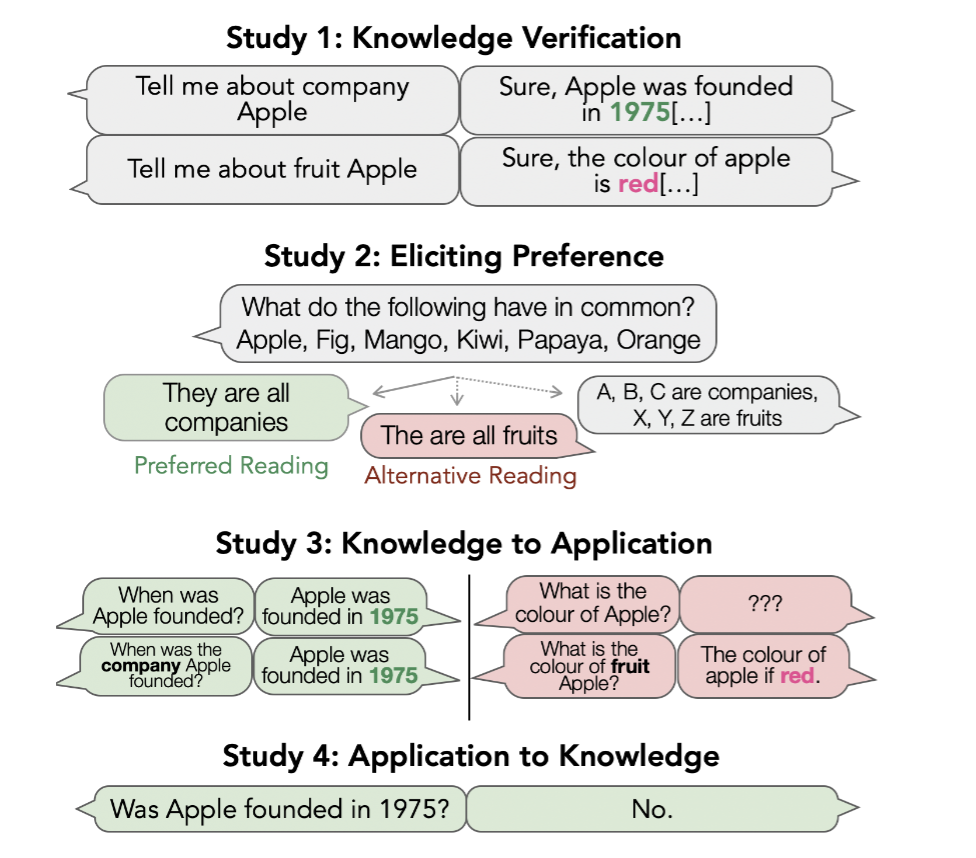 To Know or Not To Know? Analyzing Self-Consistency of Large Language Models under AmbiguityAnastasiia Sedova*, Robert Litschko*, Diego Frassinelli, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024
To Know or Not To Know? Analyzing Self-Consistency of Large Language Models under AmbiguityAnastasiia Sedova*, Robert Litschko*, Diego Frassinelli, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024One of the major aspects contributing to the striking performance of large language models (LLMs) is the vast amount of factual knowledge accumulated during pre-training. Yet, many LLMs suffer from self-inconsistency, which raises doubts about their trustworthiness and reliability. This paper focuses on entity type ambiguity, analyzing the proficiency and consistency of state-of-the-art LLMs in applying factual knowledge when prompted with ambiguous entities. To do so, we propose an evaluation protocol that disentangles knowing from applying knowledge, and test state-of-the-art LLMs on 49 ambiguous entities. Our experiments reveal that LLMs struggle with choosing the correct entity reading, achieving an average accuracy of only 85%, and as low as 75% with underspecified prompts. The results also reveal systematic discrepancies in LLM behavior, showing that while the models may possess knowledge, they struggle to apply it consistently, exhibit biases toward preferred readings, and display self-inconsistencies. This highlights the need to address entity ambiguity in the future for more trustworthy LLMs.
-
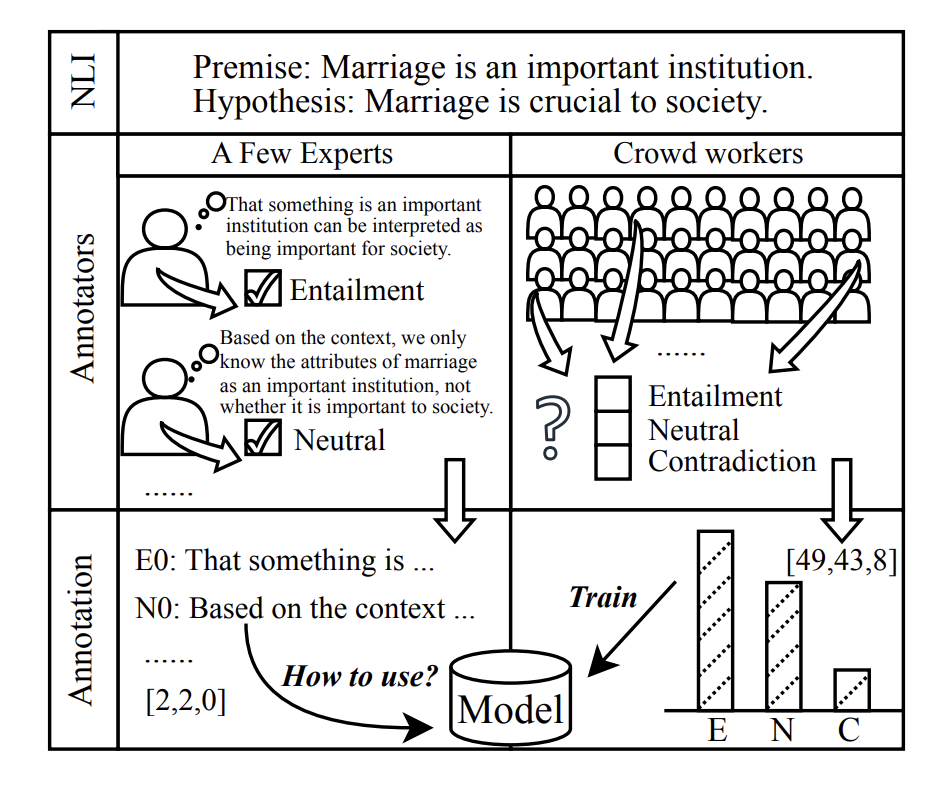 “Seeing the Big through the Small”: Can LLMs Approximate Human Judgment Distributions on NLI from a Few Explanations?Beiduo Chen, Xinpeng Wang, Siyao Peng, and 3 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024
“Seeing the Big through the Small”: Can LLMs Approximate Human Judgment Distributions on NLI from a Few Explanations?Beiduo Chen, Xinpeng Wang, Siyao Peng, and 3 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024Human label variation (HLV) is a valuable source of information that arises when multiple human annotators provide different labels for valid reasons. In Natural Language Inference (NLI) earlier approaches to capturing HLV involve either collecting annotations from many crowd workers to represent human judgment distribution (HJD) or use expert linguists to provide detailed explanations for their chosen labels. While the former method provides denser HJD information, obtaining it is resource-intensive. In contrast, the latter offers richer textual information but it is challenging to scale up to many human judges. Besides, large language models (LLMs) are increasingly used as evaluators (“LLM judges”) but with mixed results, and few works aim to study HJDs. This study proposes to exploit LLMs to approximate HJDs using a small number of expert labels and explanations. Our experiments show that a few explanations significantly improve LLMs’ ability to approximate HJDs with and without explicit labels, thereby providing a solution to scale up annotations for HJD. However, fine-tuning smaller soft-label aware models with the LLM-generated model judgment distributions (MJDs) presents partially inconsistent results: while similar in distance, their resulting fine-tuned models and visualized distributions differ substantially. We show the importance of complementing instance-level distance measures with a global-level shape metric and visualization to more effectively evaluate MJDs against human judgment distributions.
-
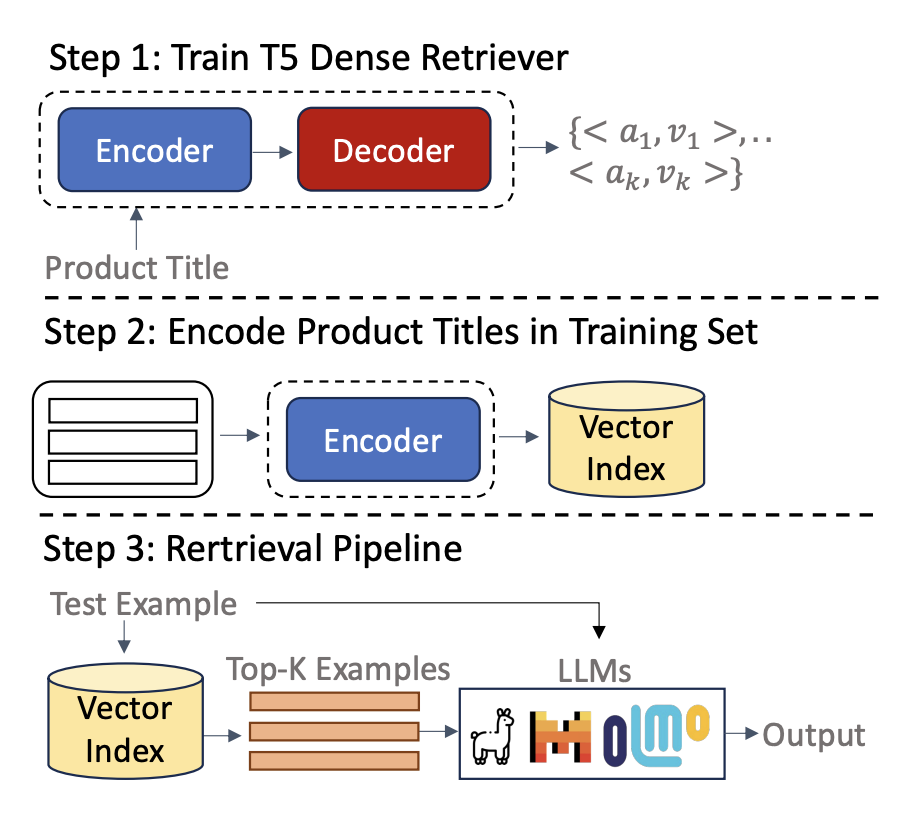 Exploring Large Language Models for Product Attribute Value IdentificationKassem Sabeh, Mouna Kacimi, Johann Gamper, and 2 more authorsarXiv preprint arXiv:2409.12695, Nov 2024
Exploring Large Language Models for Product Attribute Value IdentificationKassem Sabeh, Mouna Kacimi, Johann Gamper, and 2 more authorsarXiv preprint arXiv:2409.12695, Nov 2024Product attribute value identification (PAVI) involves automatically identifying attributes and their values from product information, enabling features like product search, recommendation, and comparison. Existing methods primarily rely on fine-tuning pre-trained language models, such as BART and T5, which require extensive task-specific training data and struggle to generalize to new attributes. This paper explores large language models (LLMs), such as LLaMA and Mistral, as data-efficient and robust alternatives for PAVI. We propose various strategies: comparing one-step and two-step prompt-based approaches in zero-shot settings and utilizing parametric and non-parametric knowledge through in-context learning examples. We also introduce a dense demonstration retriever based on a pre-trained T5 model and perform instruction fine-tuning to explicitly train LLMs on task-specific instructions. Extensive experiments on two product benchmarks show that our two-step approach significantly improves performance in zero-shot settings, and instruction fine-tuning further boosts performance when using training data, demonstrating the practical benefits of using LLMs for PAVI.
-
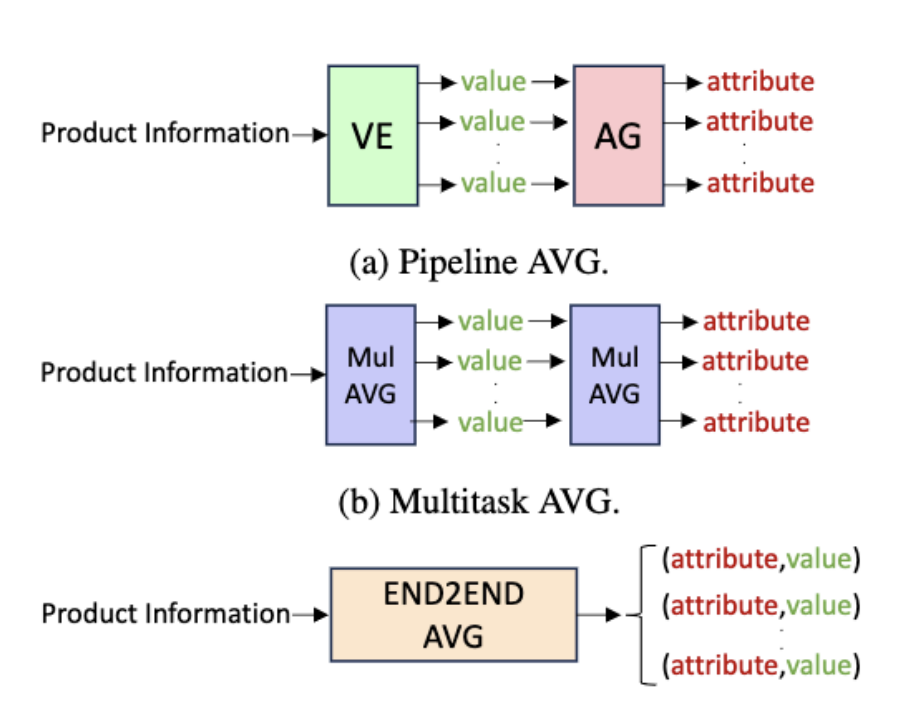 An empirical comparison of generative approaches for product attribute-value identificationKassem Sabeh, Robert Litschko, Mouna Kacimi, and 2 more authorsarXiv preprint arXiv:2407.01137, Nov 2024
An empirical comparison of generative approaches for product attribute-value identificationKassem Sabeh, Robert Litschko, Mouna Kacimi, and 2 more authorsarXiv preprint arXiv:2407.01137, Nov 2024Product attributes are crucial for e-commerce platforms, supporting applications like search, recommendation, and question answering. The task of Product Attribute and Value Identification (PAVI) involves identifying both attributes and their values from product information. In this paper, we formulate PAVI as a generation task and provide, to the best of our knowledge, the most comprehensive evaluation of PAVI so far. We compare three different attribute-value generation (AVG) strategies based on fine-tuning encoder-decoder models on three datasets. Experiments show that end-to-end AVG approach, which is computationally efficient, outperforms other strategies. However, there are differences depending on model sizes and the underlying language model.
-
 MaiNLP at SemEval-2024 Task 1: Analyzing Source Language Selection in Cross-Lingual Textual RelatednessShijia Zhou, Huangyan Shan, Barbara Plank, and 1 more authorIn Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), co-located with NAACL, Jun 2024
MaiNLP at SemEval-2024 Task 1: Analyzing Source Language Selection in Cross-Lingual Textual RelatednessShijia Zhou, Huangyan Shan, Barbara Plank, and 1 more authorIn Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), co-located with NAACL, Jun 2024This paper presents our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness (STR), on Track C: Cross-lingual. The task aims to detect semantic relatedness of two sentences from the same languages. For cross-lingual approach we developed a set of linguistics-inspired models trained with several task-specific strategies. We 1) utilize language vectors for selection of donor languages; 2) investigate the multi-source approach for training; 3) use transliteration of non-latin script to study impact of “script gap”; 4) opt machine translation for data augmentation. We additionally compare the performance of XLM-RoBERTa and Furina with the same training strategy. Our submission achieved the first place in the C8 (Kinyarwanda) test.
-
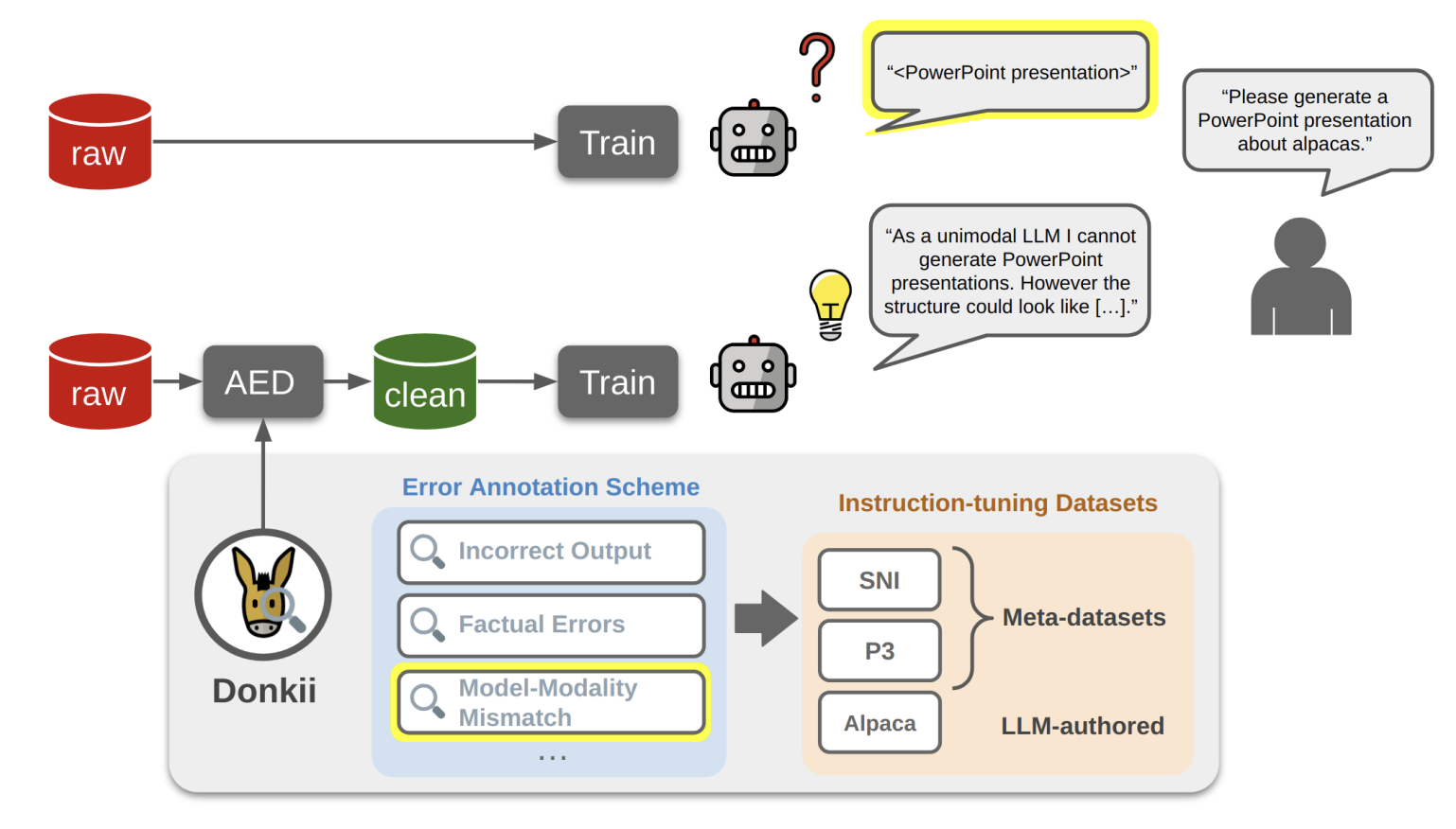 Donkii: Characterizing and Detecting Errors in Instruction-Tuning DatasetsLeon Weber, Robert Litschko, Ekaterina Artemova, and 1 more authorIn Proceedings of The 18th Linguistic Annotation Workshop (LAW-XVIII), co-located with EACL, Mar 2024
Donkii: Characterizing and Detecting Errors in Instruction-Tuning DatasetsLeon Weber, Robert Litschko, Ekaterina Artemova, and 1 more authorIn Proceedings of The 18th Linguistic Annotation Workshop (LAW-XVIII), co-located with EACL, Mar 2024Instruction tuning has become an integral part of training pipelines for Large Language Models (LLMs) and has been shown to yield strong performance gains. In an orthogonal line of research, Annotation Error Detection (AED) has emerged as a tool for detecting quality problems in gold standard labels. So far, however, the application of AED methods has been limited to classification tasks. It is an open question how well AED methods generalize to language generation settings, which are becoming more widespread via LLMs. In this paper, we present a first and novel benchmark for AED on instruction tuning data: Donkii.It comprises three instruction-tuning datasets enriched with error annotations by experts and semi-automatic methods. We also provide a novel taxonomy of error types for instruction-tuning data.We find that all three datasets contain clear errors, which sometimes propagate directly into instruction-tuned LLMs. We propose four AED baselines for the generative setting and evaluate them extensively on the newly introduced dataset. Our results show that the choice of the right AED method and model size is indeed crucial and derive practical recommendations for how to use AED methods to clean instruction-tuning data.







2023
-
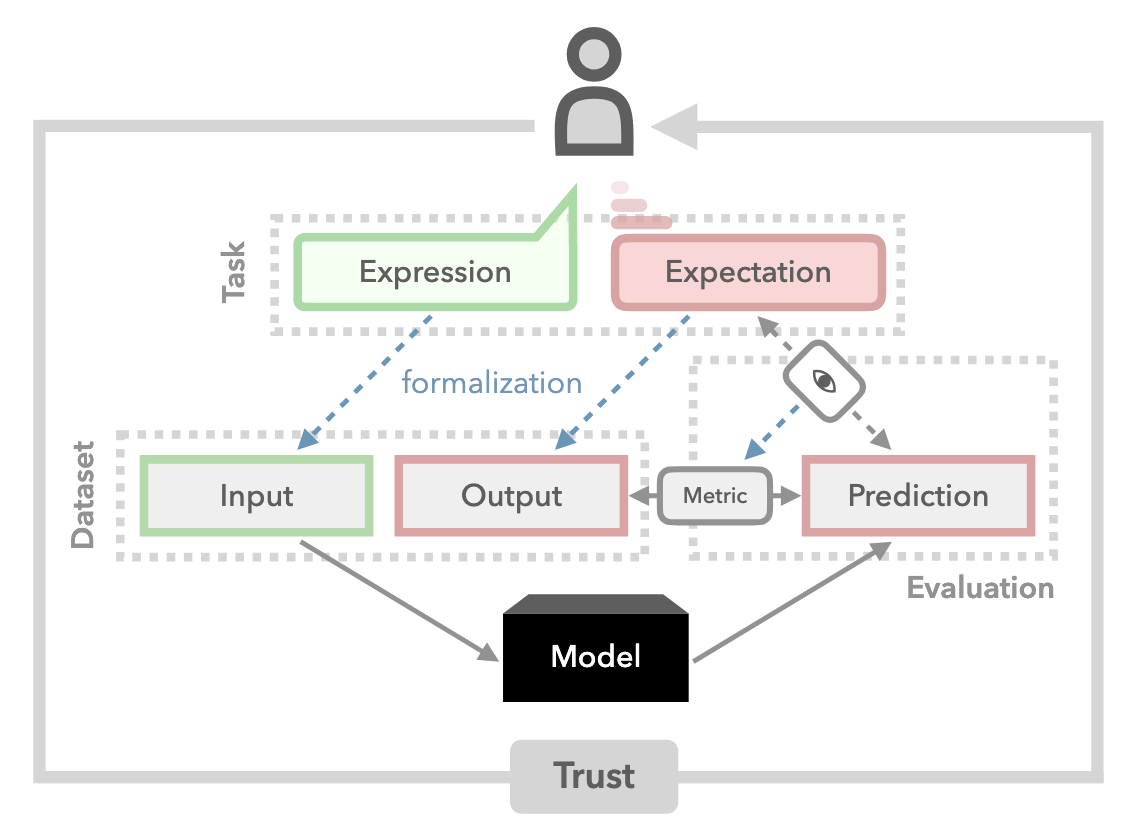 Establishing Trustworthiness: Rethinking Tasks and Model EvaluationRobert Litschko*, Max Müller-Eberstein*, Rob Goot, and 2 more authorsIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Dec 2023
Establishing Trustworthiness: Rethinking Tasks and Model EvaluationRobert Litschko*, Max Müller-Eberstein*, Rob Goot, and 2 more authorsIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Dec 2023Language understanding is a multi-faceted cognitive capability, which the Natural Language Processing (NLP) community has striven to model computationally for decades. Traditionally, facets of linguistic intelligence have been compartmentalized into tasks with specialized model architectures and corresponding evaluation protocols. With the advent of large language models (LLMs) the community has witnessed a dramatic shift towards general purpose, task-agnostic approaches powered by generative models. As a consequence, the traditional compartmentalized notion of language tasks is breaking down, followed by an increasing challenge for evaluation and analysis. At the same time, LLMs are being deployed in more real-world scenarios, including previously unforeseen zero-shot setups, increasing the need for trustworthy and reliable systems. Therefore, we argue that it is time to rethink what constitutes tasks and model evaluation in NLP, and pursue a more holistic view on language, placing trustworthiness at the center. Towards this goal, we review existing compartmentalized approaches for understanding the origins of a model‘s functional capacity, and provide recommendations for more multi-faceted evaluation protocols.
-
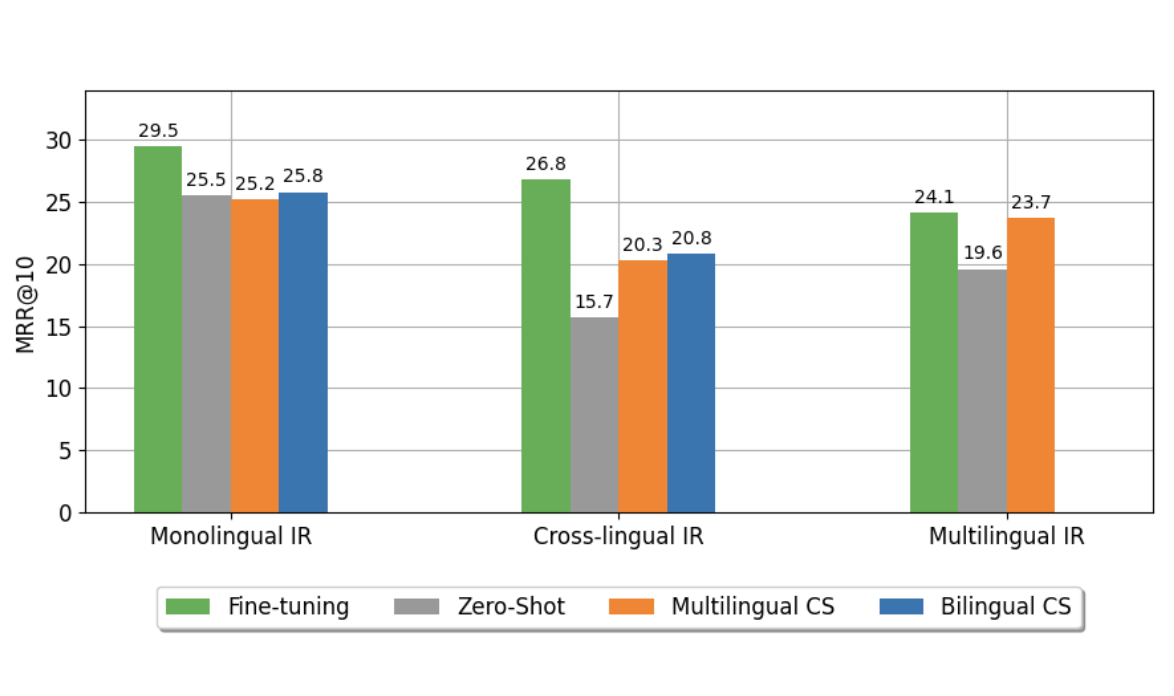 Boosting Zero-shot Cross-lingual Retrieval by Training on Artificially Code-Switched DataRobert Litschko, Ekaterina Artemova, and Barbara PlankIn Findings of the Association for Computational Linguistics: ACL 2023, Jul 2023
Boosting Zero-shot Cross-lingual Retrieval by Training on Artificially Code-Switched DataRobert Litschko, Ekaterina Artemova, and Barbara PlankIn Findings of the Association for Computational Linguistics: ACL 2023, Jul 2023Transferring information retrieval (IR) models from a high-resource language (typically English) to other languages in a zero-shot fashion has become a widely adopted approach. In this work, we show that the effectiveness of zero-shot rankers diminishes when queries and documents are present in different languages. Motivated by this, we propose to train ranking models on artificially code-switched data instead, which we generate by utilizing bilingual lexicons. To this end, we experiment with lexicons induced from (1) cross-lingual word embeddings and (2) parallel Wikipedia page titles. We use the mMARCO dataset to extensively evaluate reranking models on 36 language pairs spanning Monolingual IR (MoIR), Cross-lingual IR (CLIR), and Multilingual IR (MLIR). Our results show that code-switching can yield consistent and substantial gains of 5.1 MRR@10 in CLIR and 3.9 MRR@10 in MLIR, while maintaining stable performance in MoIR. Encouragingly, the gains are especially pronounced for distant languages (up to 2x absolute gain). We further show that our approach is robust towards the ratio of code-switched tokens and also extends to unseen languages. Our results demonstrate that training on code-switched data is a cheap and effective way of generalizing zero-shot rankers for cross-lingual and multilingual retrieval.
-
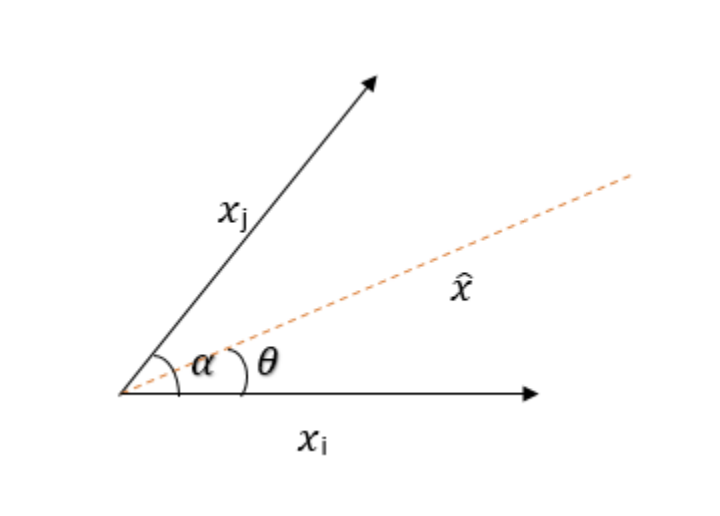 Vicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language DetectionGretel Peña Sarracén, Paolo Rosso, Robert Litschko, and 2 more authorsIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Dec 2023
Vicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language DetectionGretel Peña Sarracén, Paolo Rosso, Robert Litschko, and 2 more authorsIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Dec 2023Cross-lingual transfer learning from high-resource to medium and low-resource languages has shown encouraging results. However, the scarcity of resources in target languages remains a challenge. In this work, we resort to data augmentation and continual pre-training for domain adaptation to improve cross-lingual abusive language detection. For data augmentation, we analyze two existing techniques based on vicinal risk minimization and propose MIXAG, a novel data augmentation method which interpolates pairs of instances based on the angle of their representations. Our experiments involve seven languages typologically distinct from English and three different domains. The results reveal that the data augmentation strategies can enhance few-shot cross-lingual abusive language detection. Specifically, we observe that consistently in all target languages, MIXAG improves significantly in multidomain and multilingual environments. Finally, we show through an error analysis how the domain adaptation can favour the class of abusive texts (reducing false negatives), but at the same time, declines the precision of the abusive language detection model.
-
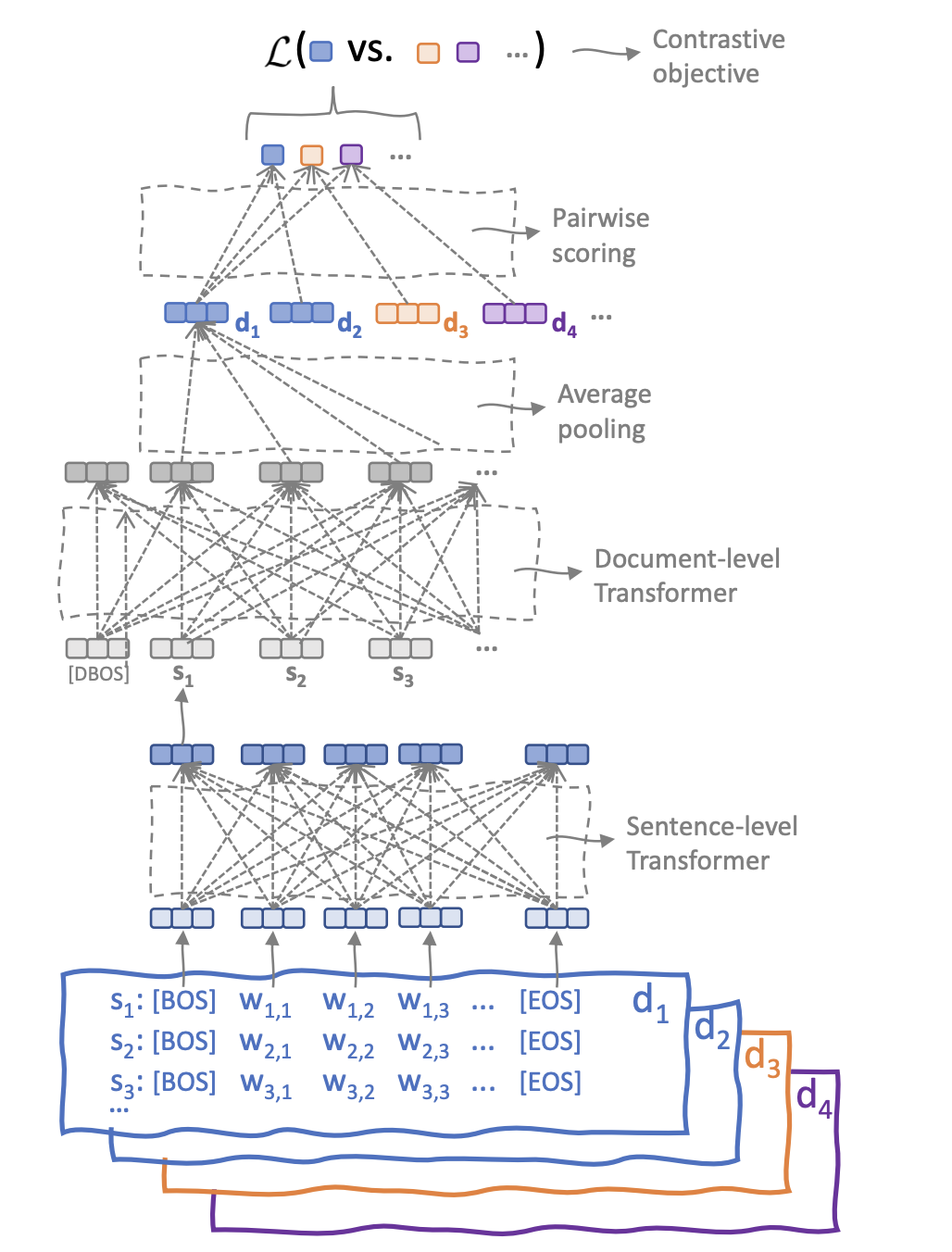 A General-Purpose Multilingual Document EncoderOnur Galoğlu Robert Litschko, Robert Litschko, and Goran GlavašIn Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL), co-located with EMNLP, Dec 2023
A General-Purpose Multilingual Document EncoderOnur Galoğlu Robert Litschko, Robert Litschko, and Goran GlavašIn Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL), co-located with EMNLP, Dec 2023Massively multilingual pretrained transformers (MMTs) have tremendously pushed the state of the art on multilingual NLP and cross-lingual transfer of NLP models in particular. While a large body of work leveraged MMTs to mine parallel data and induce bilingual document embeddings, much less effort has been devoted to training general-purpose (massively) multilingual document encoder that can be used for both supervised and unsupervised document-level tasks. In this work, we pretrain a massively multilingual document encoder as a hierarchical transformer model (HMDE) in which a shallow document transformer contextualizes sentence representations produced by a state-of-the-art pretrained multilingual sentence encoder. We leverage Wikipedia as a readily available source of comparable documents for creating training data, and train HMDE by means of a cross-lingual contrastive objective, further exploiting the category hierarchy of Wikipedia for creation of difficult negatives. We evaluate the effectiveness of HMDE in two arguably most common and prominent cross-lingual document-level tasks: (1) cross-lingual transfer for topical document classification and (2) cross-lingual document retrieval. HMDE is significantly more effective than (i) aggregations of segment-based representations and (ii) multilingual Longformer. Crucially, owing to its massively multilingual lower transformer, HMDE successfully generalizes to languages unseen in document-level pretraining.




2022
-
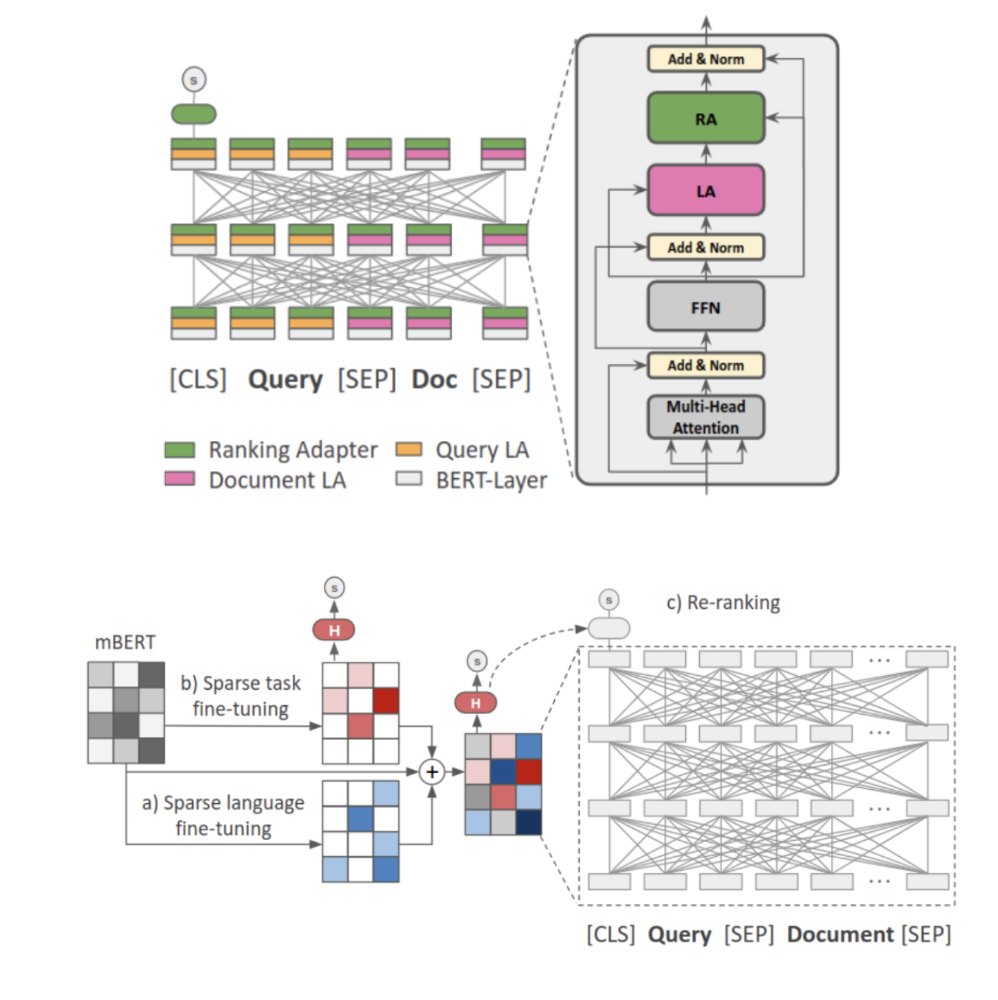 Parameter-Efficient Neural Reranking for Cross-Lingual and Multilingual RetrievalRobert Litschko, Ivan Vulić, and Goran GlavašIn Proceedings of the 29th International Conference on Computational Linguistics (COLING), Oct 2022
Parameter-Efficient Neural Reranking for Cross-Lingual and Multilingual RetrievalRobert Litschko, Ivan Vulić, and Goran GlavašIn Proceedings of the 29th International Conference on Computational Linguistics (COLING), Oct 2022State-of-the-art neural (re)rankers are notoriously data-hungry which – given the lack of large-scale training data in languages other than English – makes them rarely used in multilingual and cross-lingual retrieval settings. Current approaches therefore commonly transfer rankers trained on English data to other languages and cross-lingual setups by means of multilingual encoders: they fine-tune all parameters of pretrained massively multilingual Transformers (MMTs, e.g., multilingual BERT) on English relevance judgments, and then deploy them in the target language(s). In this work, we show that two parameter-efficient approaches to cross-lingual transfer, namely Sparse Fine-Tuning Masks (SFTMs) and Adapters, allow for a more lightweight and more effective zero-shot transfer to multilingual and cross-lingual retrieval tasks. We first train language adapters (or SFTMs) via Masked Language Modelling and then train retrieval (i.e., reranking) adapters (SFTMs) on top, while keeping all other parameters fixed. At inference, this modular design allows us to compose the ranker by applying the (re)ranking adapter (or SFTM) trained with source language data together with the language adapter (or SFTM) of a target language. We carry out a large scale evaluation on the CLEF-2003 and HC4 benchmarks and additionally, as another contribution, extend the former with queries in three new languages: Kyrgyz, Uyghur and Turkish. The proposed parameter-efficient methods outperform standard zero-shot transfer with full MMT fine-tuning, while being more modular and reducing training times. The gains are particularly pronounced for low-resource languages, where our approaches also substantially outperform the competitive machine translation-based rankers.
-
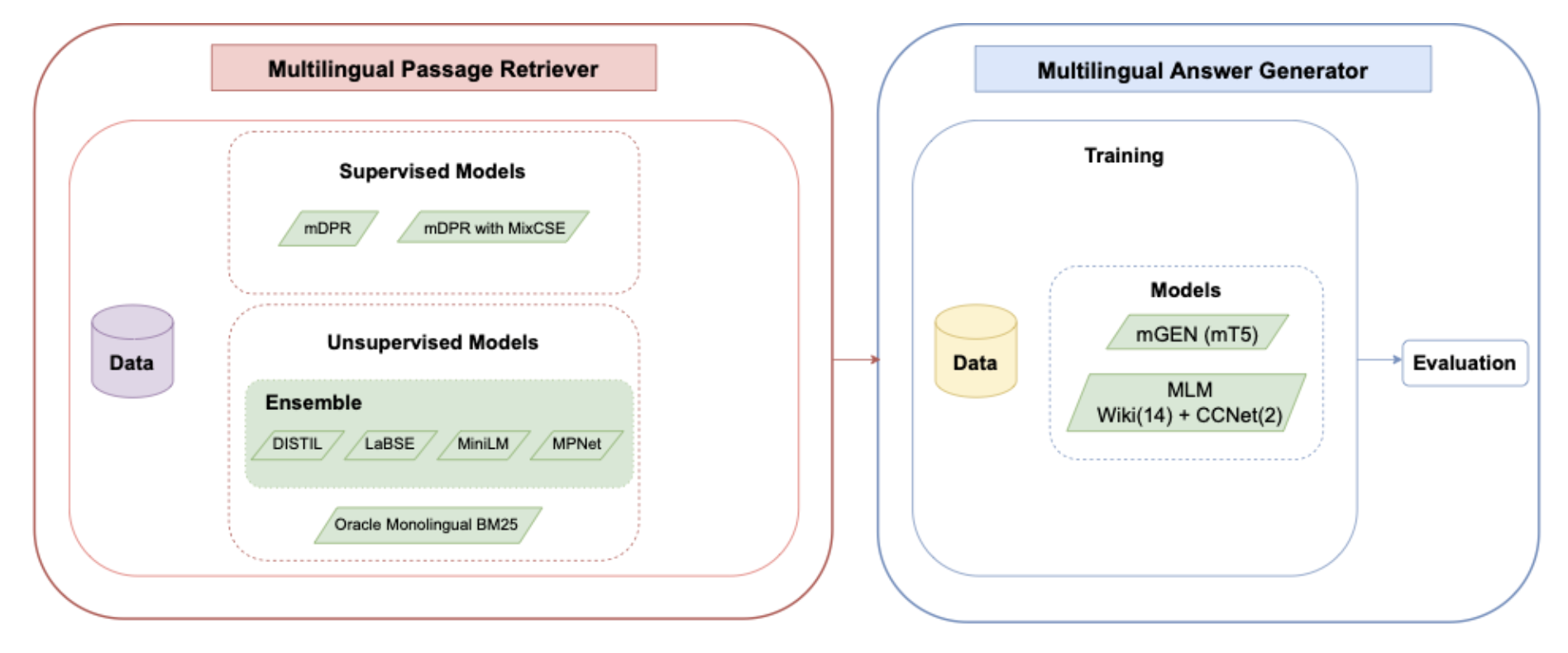 ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering SystemChia-Chien Hung, Tommaso Green, Robert Litschko, and 5 more authorsIn Proceedings of the Workshop on Multilingual Information Access (MIA), co-located with NAACL, Jul 2022
ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering SystemChia-Chien Hung, Tommaso Green, Robert Litschko, and 5 more authorsIn Proceedings of the Workshop on Multilingual Information Access (MIA), co-located with NAACL, Jul 2022This paper introduces our proposed system for the MIA Shared Task on Cross-lingual Openretrieval Question Answering (COQA). In this challenging scenario, given an input question the system has to gather evidence documents from a multilingual pool and generate from them an answer in the language of the question. We devised several approaches combining different model variants for three main components: Data Augmentation, Passage Retrieval, and Answer Generation. For passage retrieval, we evaluated the monolingual BM25 ranker against the ensemble of re-rankers based on multilingual pretrained language models (PLMs) and also variants of the shared task baseline, re-training it from scratch using a recently introduced contrastive loss that maintains a strong gradient signal throughout training by means of mixed negative samples. For answer generation, we focused on languageand domain-specialization by means of continued language model (LM) pretraining of existing multilingual encoders. Additionally, for both passage retrieval and answer generation, we augmented the training data provided by the task organizers with automatically generated question-answer pairs created from Wikipedia passages to mitigate the issue of data scarcity, particularly for the low-resource languages for which no training data were provided. Our results show that language- and domain-specialization as well as data augmentation help, especially for low-resource languages.
-
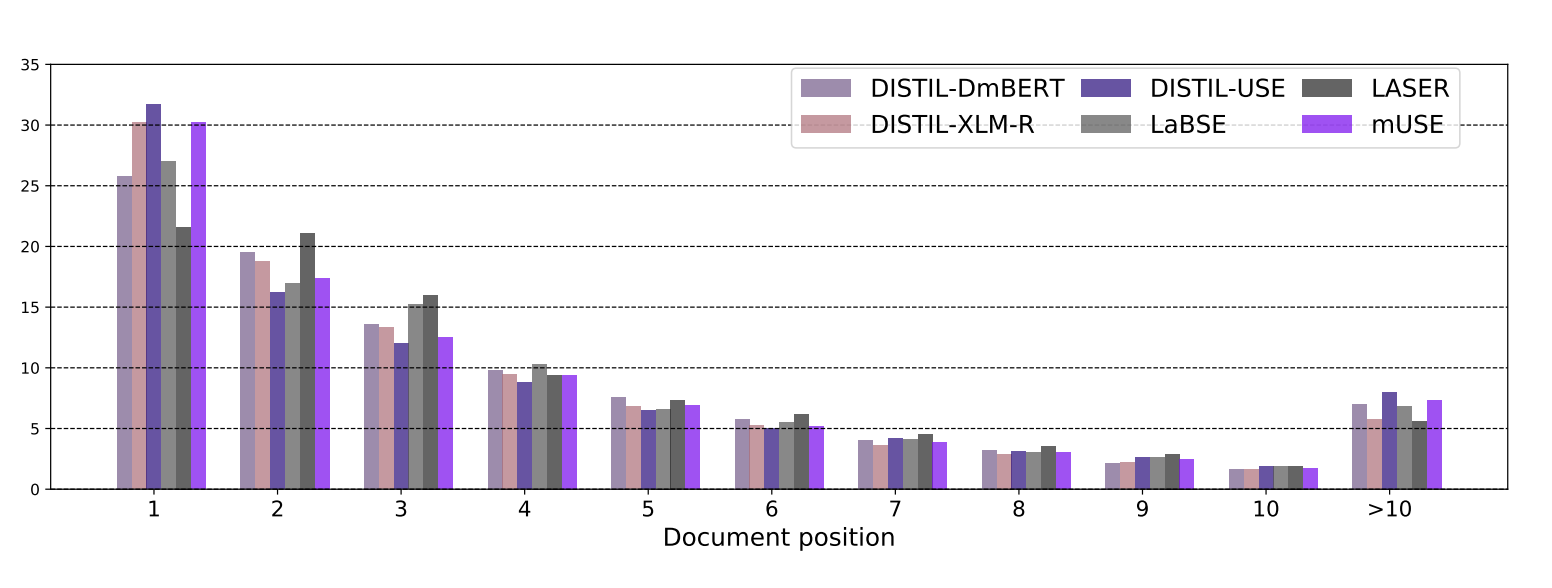 On cross-lingual retrieval with multilingual text encodersRobert Litschko, Ivan Vulić, Simone Paolo Ponzetto, and 1 more authorInformation Retrieval Journal, Jul 2022
On cross-lingual retrieval with multilingual text encodersRobert Litschko, Ivan Vulić, Simone Paolo Ponzetto, and 1 more authorInformation Retrieval Journal, Jul 2022In this work we present a systematic empirical study focused on the suitability of the state-of-the-art multilingual encoders for cross-lingual document and sentence retrieval tasks across a number of diverse language pairs. We first treat these models as multilingual text encoders and benchmark their performance in unsupervised ad-hoc sentence- and document-level CLIR. In contrast to supervised language understanding, our results indicate that for unsupervised document-level CLIR – a setup with no relevance judgments for IR-specific fine-tuning – pretrained multilingual encoders on average fail to significantly outperform earlier models based on CLWEs. For sentence-level retrieval, we do obtain state-of-the-art performance: the peak scores, however, are met by multilingual encoders that have been further specialized, in a supervised fashion, for sentence understanding tasks, rather than using their vanilla ’off-the-shelf’ variants. Following these results, we introduce localized relevance matching for document-level CLIR, where we independently score a query against document sections. In the second part, we evaluate multilingual encoders fine-tuned in a supervised fashion (i.e., we learn to rank) on English relevance data in a series of zero-shot language and domain transfer CLIR experiments. Our results show that supervised re-ranking rarely improves the performance of multilingual transformers as unsupervised base rankers. Finally, only with in-domain contrastive fine-tuning (i.e., same domain, only language transfer), we manage to improve the ranking quality. We uncover substantial empirical differences between cross-lingual retrieval results and results of (zero-shot) cross-lingual transfer for monolingual retrieval in target languages, which point to “monolingual overfitting” of retrieval models trained on monolingual data.



2021
-
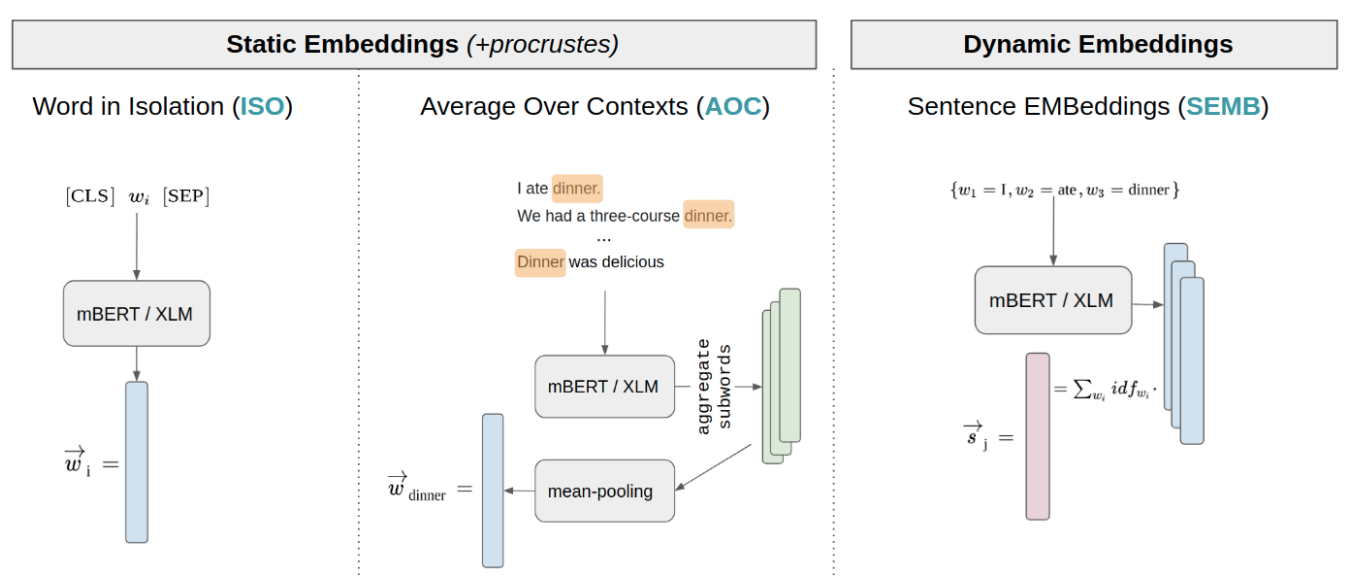 Evaluating multilingual text encoders for unsupervised cross-lingual retrievalRobert Litschko, Ivan Vulić, Simone Paolo Ponzetto, and 1 more authorIn Advances in Information Retrieval: 43rd European Conference on IR Research (ECIR), Jul 2021
Evaluating multilingual text encoders for unsupervised cross-lingual retrievalRobert Litschko, Ivan Vulić, Simone Paolo Ponzetto, and 1 more authorIn Advances in Information Retrieval: 43rd European Conference on IR Research (ECIR), Jul 2021Pretrained multilingual text encoders based on neural Transformer architectures, such as multilingual BERT (mBERT) and XLM, have achieved strong performance on a myriad of language understanding tasks. Consequently, they have been adopted as a go-to paradigm for multilingual and cross-lingual representation learning and transfer, rendering cross-lingual word embeddings (CLWEs) effectively obsolete. However, questions remain to which extent this finding generalizes 1) to unsupervised settings and 2) for ad-hoc cross-lingual IR (CLIR) tasks. Therefore, in this work we present a systematic empirical study focused on the suitability of the state-of-the-art multilingual encoders for cross-lingual document and sentence retrieval tasks across a large number of language pairs. In contrast to supervised language understanding, our results indicate that for unsupervised document-level CLIR – a setup with no relevance judgments for IR-specific fine-tuning – pretrained encoders fail to significantly outperform models based on CLWEs. For sentence-level CLIR, we demonstrate that state-of-the-art performance can be achieved. However, the peak performance is not met using the general-purpose multilingual text encoders ‘off-the-shelf’, but rather relying on their variants that have been further specialized for sentence understanding tasks.

2020
-
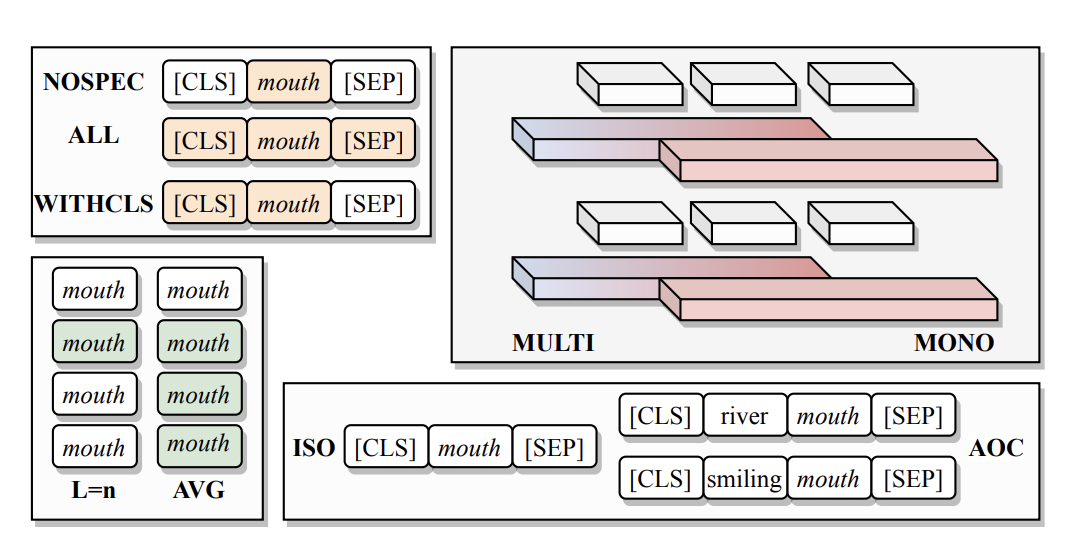 Probing Pretrained Language Models for Lexical SemanticsIvan Vulić, Edoardo Maria Ponti, Robert Litschko, and 2 more authorsIn Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Nov 2020
Probing Pretrained Language Models for Lexical SemanticsIvan Vulić, Edoardo Maria Ponti, Robert Litschko, and 2 more authorsIn Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Nov 2020The success of large pretrained language models (LMs) such as BERT and RoBERTa has sparked interest in probing their representations, in order to unveil what types of knowledge they implicitly capture. While prior research focused on morphosyntactic, semantic, and world knowledge, it remains unclear to which extent LMs also derive lexical type-level knowledge from words in context. In this work, we present a systematic empirical analysis across six typologically diverse languages and five different lexical tasks, addressing the following questions: 1) How do different lexical knowledge extraction strategies (monolingual versus multilingual source LM, out-of-context versus in-context encoding, inclusion of special tokens, and layer-wise averaging) impact performance? How consistent are the observed effects across tasks and languages? 2) Is lexical knowledge stored in few parameters, or is it scattered throughout the network? 3) How do these representations fare against traditional static word vectors in lexical tasks 4) Does the lexical information emerging from independently trained monolingual LMs display latent similarities? Our main results indicate patterns and best practices that hold universally, but also point to prominent variations across languages and tasks. Moreover, we validate the claim that lower Transformer layers carry more type-level lexical knowledge, but also show that this knowledge is distributed across multiple layers.
-
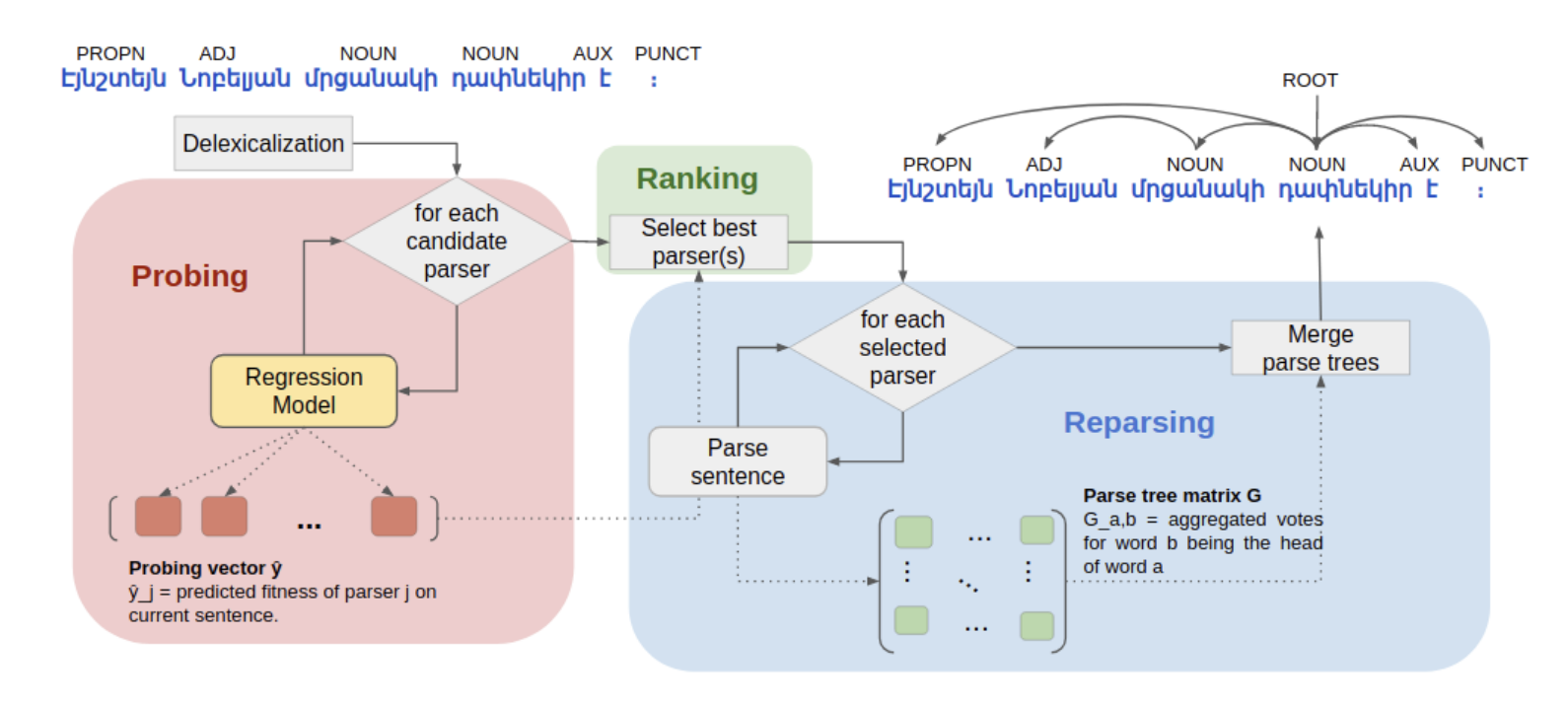 Towards Instance-Level Parser Selection for Cross-Lingual Transfer of Dependency ParsersRobert Litschko, Ivan Vulić, Željko Agić, and 1 more authorIn Proceedings of the 28th International Conference on Computational Linguistics (COLING), Dec 2020
Towards Instance-Level Parser Selection for Cross-Lingual Transfer of Dependency ParsersRobert Litschko, Ivan Vulić, Željko Agić, and 1 more authorIn Proceedings of the 28th International Conference on Computational Linguistics (COLING), Dec 2020Current methods of cross-lingual parser transfer focus on predicting the best parser for a low-resource target language globally, that is, “at treebank level”. In this work, we propose and argue for a novel cross-lingual transfer paradigm: instance-level parser selection (ILPS), and present a proof-of-concept study focused on instance-level selection in the framework of delexicalized parser transfer. Our work is motivated by an empirical observation that different source parsers are the best choice for different Universal POS-sequences (i.e., UPOS sentences) in the target language. We then propose to predict the best parser at the instance level. To this end, we train a supervised regression model, based on the Transformer architecture, to predict parser accuracies for individual POS-sequences. We compare ILPS against two strong single-best parser selection baselines (SBPS): (1) a model that compares POS n-gram distributions between the source and target languages (KL) and (2) a model that selects the source based on the similarity between manually created language vectors encoding syntactic properties of languages (L2V). The results from our extensive evaluation, coupling 42 source parsers and 20 diverse low-resource test languages, show that ILPS outperforms KL and L2V on 13/20 and 14/20 test languages, respectively. Further, we show that by predicting the best parser “at treebank level” (SBPS), using the aggregation of predictions from our instance-level model, we outperform the same baselines on 17/20 and 16/20 test languages.


2019
- SIGIR 19Evaluating resource-lean cross-lingual embedding models in unsupervised retrievalRobert Litschko, Goran Glavaš, Ivan Vulic, and 1 more authorIn Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval, Dec 2019
We propose a fully unsupervised framework for ad-hoc cross-lingual information retrieval (CLIR) which requires no bilingual data at all. The framework leverages shared cross-lingual word embedding spaces in which terms, queries, and documents can be represented, irrespective of their actual language. The shared embedding spaces are induced solely on the basis of monolingual corpora in two languages through an iterative process based on adversarial neural networks. Our experiments on the standard CLEF CLIR collections for three language pairs of varying degrees of language similarity (English-Dutch/Italian/Finnish) demonstrate the usefulness of the proposed fully unsupervised approach. Our CLIR models with unsupervised cross-lingual embeddings outperform baselines that utilize cross-lingual embeddings induced relying on word-level and document-level alignments. We then demonstrate that further improvements can be achieved by unsupervised ensemble CLIR models. We believe that the proposed framework is the first step towards development of effective CLIR models for language pairs and domains where parallel data are scarce or non-existent.
-
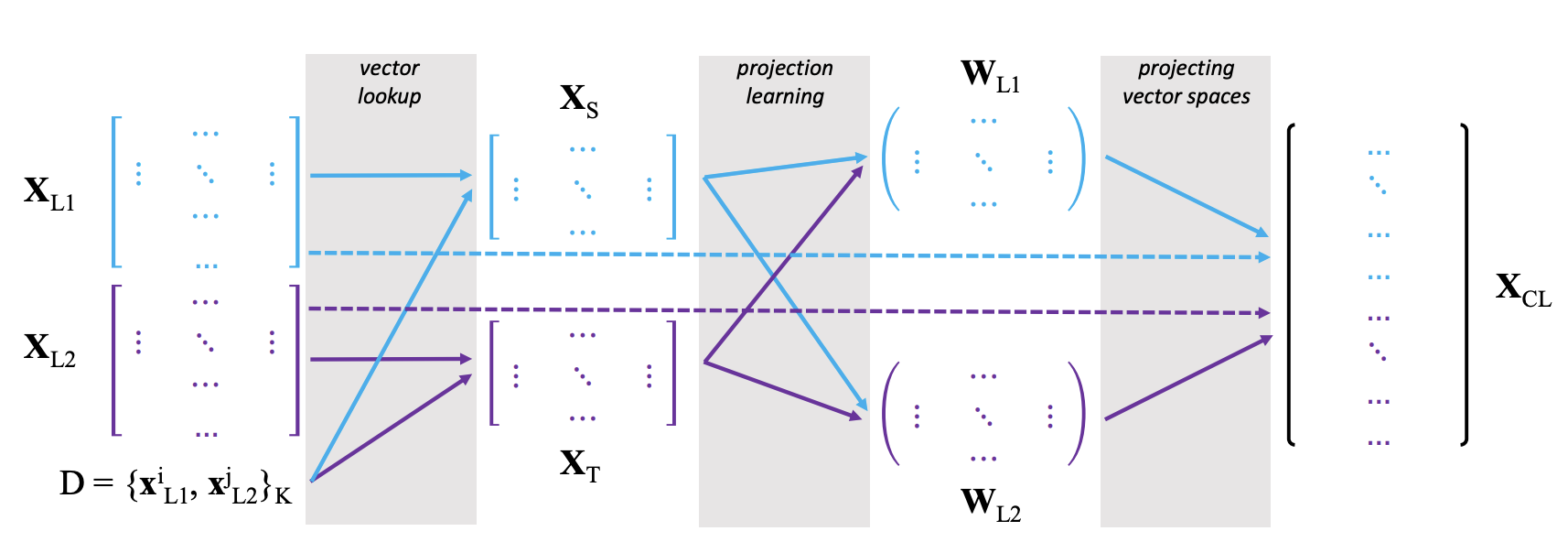 How to (Properly) Evaluate Cross-Lingual Word Embeddings: On Strong Baselines, Comparative Analyses, and Some MisconceptionsGoran Glavaš, Robert Litschko, Sebastian Ruder, and 1 more authorIn Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Jul 2019
How to (Properly) Evaluate Cross-Lingual Word Embeddings: On Strong Baselines, Comparative Analyses, and Some MisconceptionsGoran Glavaš, Robert Litschko, Sebastian Ruder, and 1 more authorIn Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Jul 2019Cross-lingual word embeddings (CLEs) facilitate cross-lingual transfer of NLP models. Despite their ubiquitous downstream usage, increasingly popular projection-based CLE models are almost exclusively evaluated on bilingual lexicon induction (BLI). Even the BLI evaluations vary greatly, hindering our ability to correctly interpret performance and properties of different CLE models. In this work, we take the first step towards a comprehensive evaluation of CLE models: we thoroughly evaluate both supervised and unsupervised CLE models, for a large number of language pairs, on BLI and three downstream tasks, providing new insights concerning the ability of cutting-edge CLE models to support cross-lingual NLP. We empirically demonstrate that the performance of CLE models largely depends on the task at hand and that optimizing CLE models for BLI may hurt downstream performance. We indicate the most robust supervised and unsupervised CLE models and emphasize the need to reassess simple baselines, which still display competitive performance across the board. We hope our work catalyzes further research on CLE evaluation and model analysis.

2018
- SIGIR 18Unsupervised cross-lingual information retrieval using monolingual data onlyRobert Litschko, Goran Glavaš, Simone Paolo Ponzetto, and 1 more authorIn The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Jul 2018
We propose a fully unsupervised framework for ad-hoc cross-lingual information retrieval (CLIR) which requires no bilingual data at all. The framework leverages shared cross-lingual word embedding spaces in which terms, queries, and documents can be represented, irrespective of their actual language. The shared embedding spaces are induced solely on the basis of monolingual corpora in two languages through an iterative process based on adversarial neural networks. Our experiments on the standard CLEF CLIR collections for three language pairs of varying degrees of language similarity (English-Dutch/Italian/Finnish) demonstrate the usefulness of the proposed fully unsupervised approach. Our CLIR models with unsupervised cross-lingual embeddings outperform baselines that utilize cross-lingual embeddings induced relying on word-level and document-level alignments. We then demonstrate that further improvements can be achieved by unsupervised ensemble CLIR models. We believe that the proposed framework is the first step towards development of effective CLIR models for language pairs and domains where parallel data are scarce or non-existent.